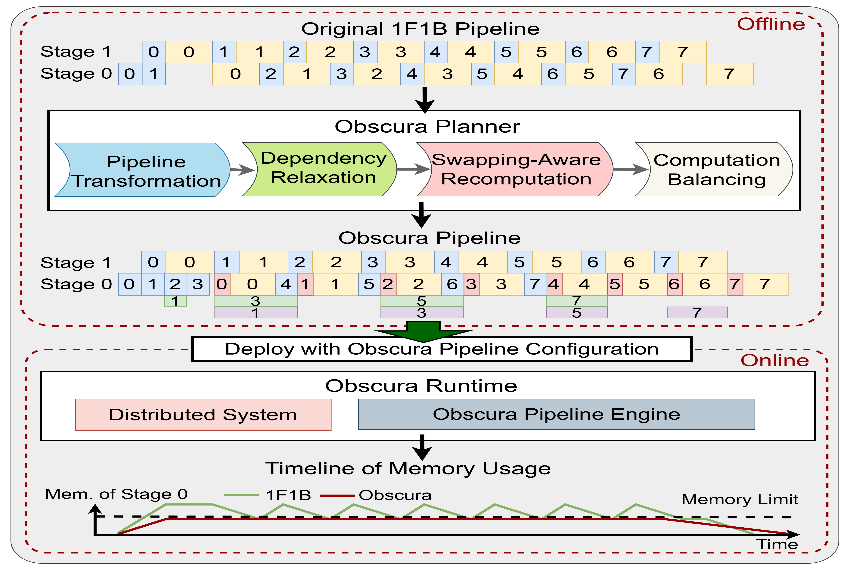
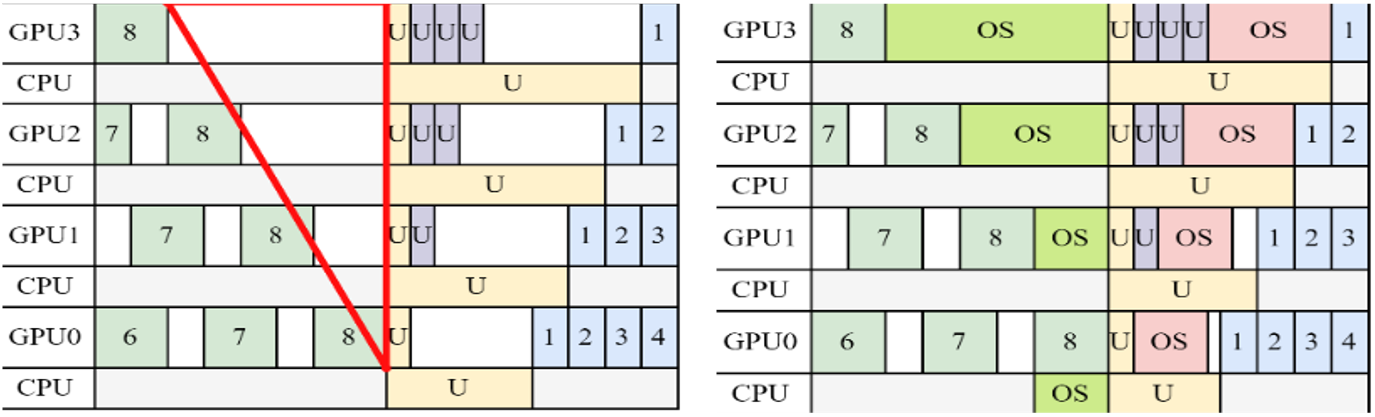
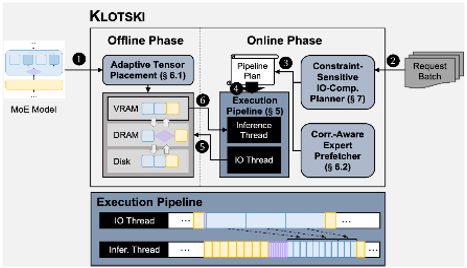
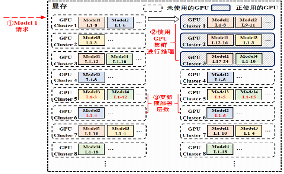
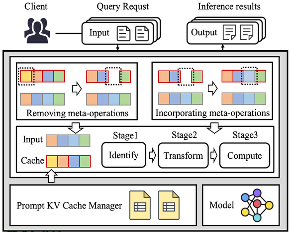
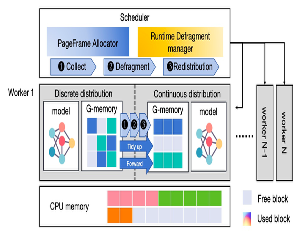
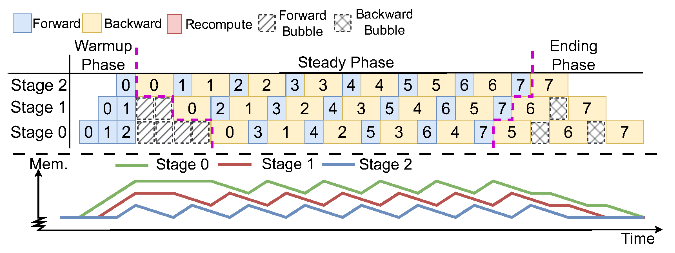
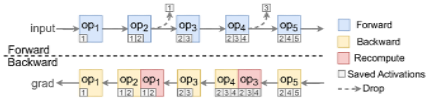
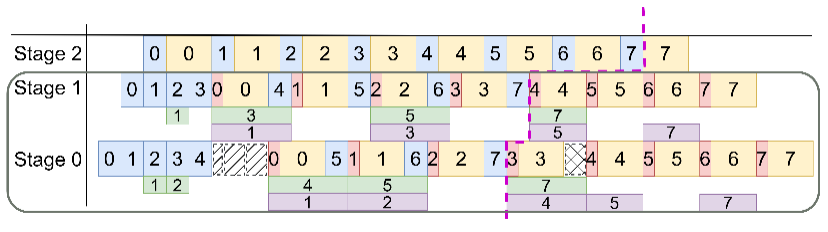
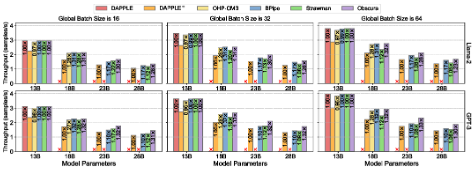
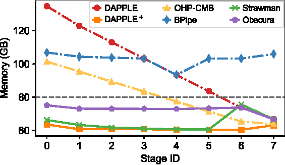
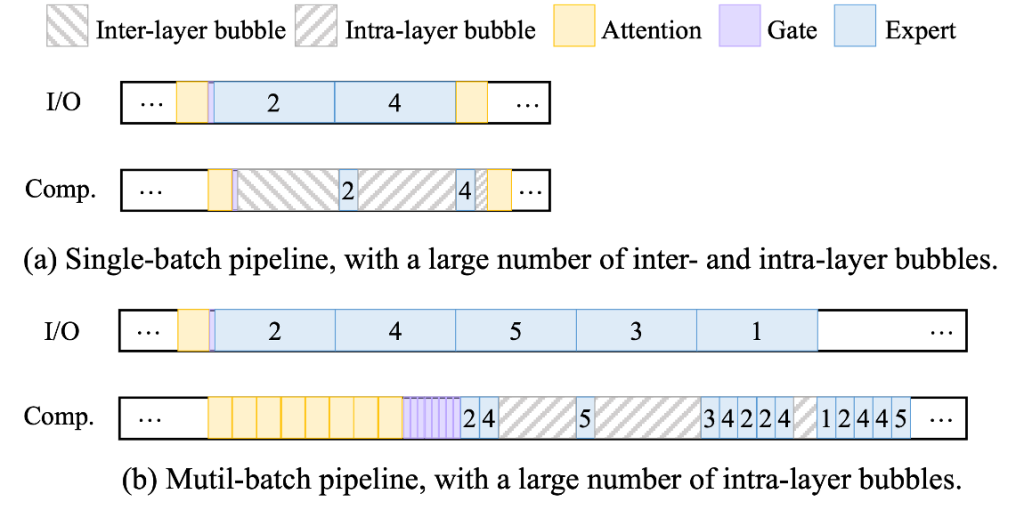
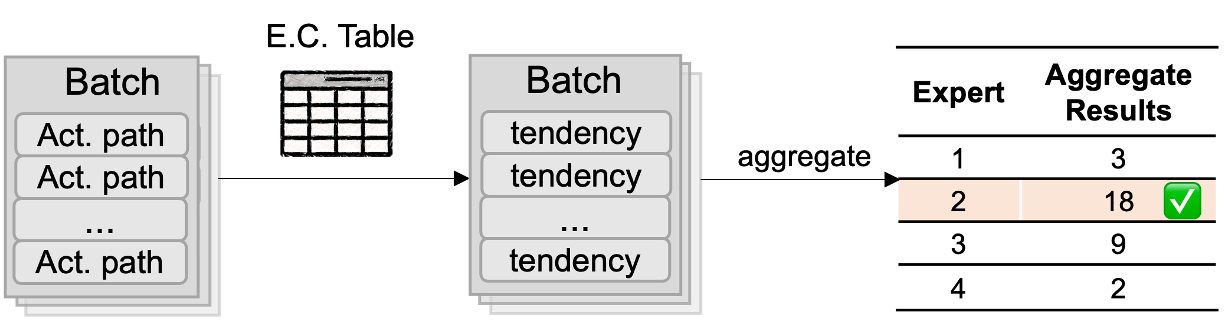
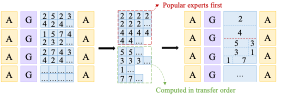
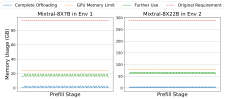
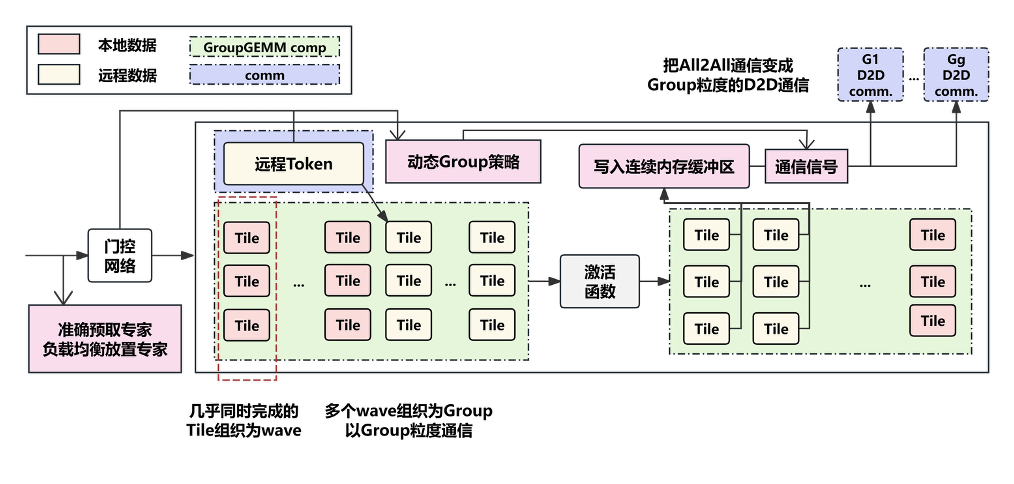
推理加速 基于网算存一体协同优化的大模型训练/推理加速 研究目标: 高性能训练与推理系统 大模型训练加速 新型流水线并行,加速训练32% 协同优化器更新,吞吐量提升30% 大模型推理加速 低显存MoE推理 吞吐量提升15倍 多模型协同推理 提升吞吐量42% KV-cache共享 降低时延22% KV-cache动态存储 减少90%迁移开销 大模型训练加速技术 大模型训练加速技术 大模型训练加速技术-扩展 面向大规模分布式 MoE 的通算融合优化 国产昇腾生态适配技术 企业合作项目:大模型训练加速技术 研究问题:基于空泡填充的流水线转换隐藏重计算开销,并协同交换和阶段划分调整技术以解决转换所带来的额外显存占用和计算不平衡问题,实现22%-32%的训练吞吐量提升,成果正在落地华为MindSpore 科学问题 流水线并行策略存在明显的显存占用不平衡现象,早期阶段成为显存瓶颈重计算技术通过丢弃激活值能够有效降低显存占用,但会引入高昂的计算开销 解决思路 流水线转换,通过空泡迁移以隐藏重计算开销交换感知重计算,通过结合交换技术和细粒度重计算以高效满足显存限制阶段划分调整,转移模型层以平衡计算 实验结果 吞吐量提升:最高32% 显存占用下降:44% 企业合作项目:MoE大模型推理加速技术 研究内容:提出基于热门专家的预取,重编排多batch的计算图,以实现对层间气泡和层内气泡的极致压缩,进而大幅提升MoE模型推理的吞吐量,成果已转换为MindSpore版本,兼容国产昇腾910B 科学问题 MoE模型面临严重的显存瓶颈。现有卸载方案低效,推理流水线存在大量气泡如何预取专家可以减少层间气泡?如何编排计算可以减少层内气泡? 解决思路 硬件感知的张量放置基于专家激活路径的热门专家预取专家感知的多batch计算图编排算法 实验结果 吞吐量提升:最高85.12X显存需求:最高可降低超90% 企业合作项目:MoE大模型推理加速技术 研究问题:端侧MoE推理对内存需求大,而专家预取准确度低,大量I/O导致传输延迟高,推理流水线气泡多 解决思路 跨层专家预取: CPU,高准确度且无额外开销Depth-aware 专家缓存:倾向浅层缓存Popularity-aware 混合量化:传输 INT 4/2 实验结果 专家预取准确度:97.15% 缓存后的专家命中率:99.08% 量化策略带来的精度损失:约1% 实验:3090, Qwen1.5-MoE, gen_len=32 Ours: 7.02 s Accelerate: 37.76 s Accelerate (all in mem): 6.98 s 企业合作项目:面向大规模分布式 MoE 的通算融合优化 研究问题:MoE推理通信开销大。细粒度通信时I/O碎片化,通信地址不连续导致带宽利用率低 解决思路 核心思路:GEMM矩阵切成Tile,Tile->Wave->Group细粒度重叠通信/计算,先来先计算,将All2All通信优化成D2D通信 关键技术: 动态Group划分:动态计算最佳划分策略 通讯数据地址连续化:GEMM与通信Kernel融合,直接连续化写入独立缓存区 负载均衡:优化专家放置,兼顾通信与负载均衡 企业合作项目:国产昇腾生态适配技术 研究背景:模型国产化迁移面临诸多挑战,主要分为:(1)企业硬件资源受限,主流工业大模型部署困难(2)跨平台模型转换流程繁琐 (3) 模型代码配置文件需频繁人工更新 异构融合推理系统 异构资源策略调度KV cache高效管理模型权重动态加载 综合资源利用率≥80%显存需求降低约 90%推理吞吐量提升1倍 轻量化部署工具 实现训练数据格式一键转换实现并行训练策略一键自动配置实现权重一键自动切分实现权重冗余参数一键自动过滤实现权重一键自动合并与转换 代码自动生成 基于已有代码生成模型,微调出适用于transformer模型文件到mindspore版本文件自动转换的代码生成模型实现基于mindspore的模型文件随transformer库升级而自动更新