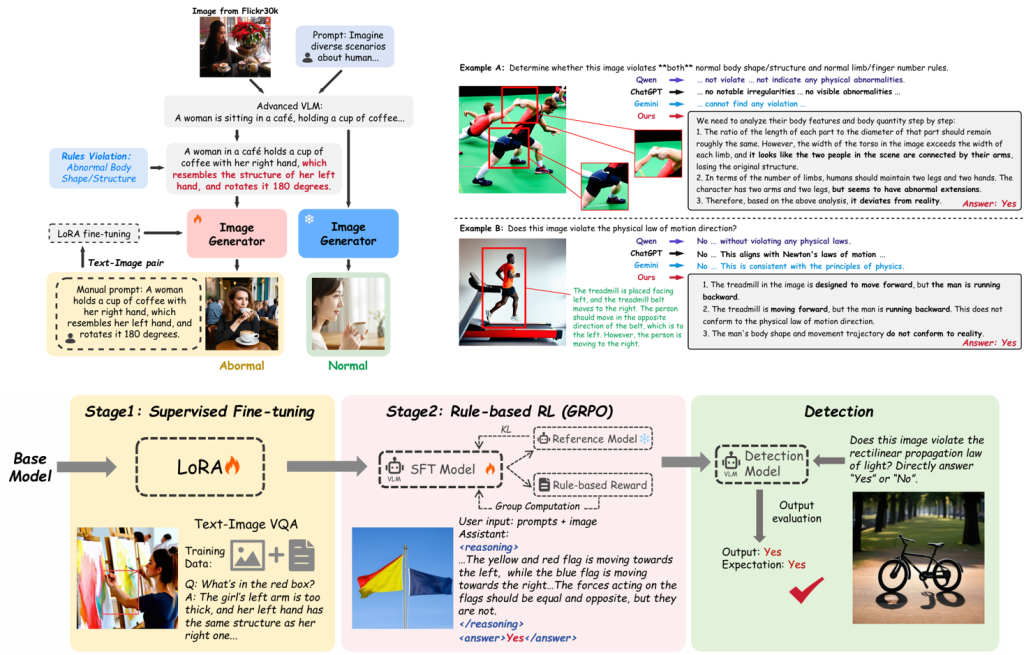
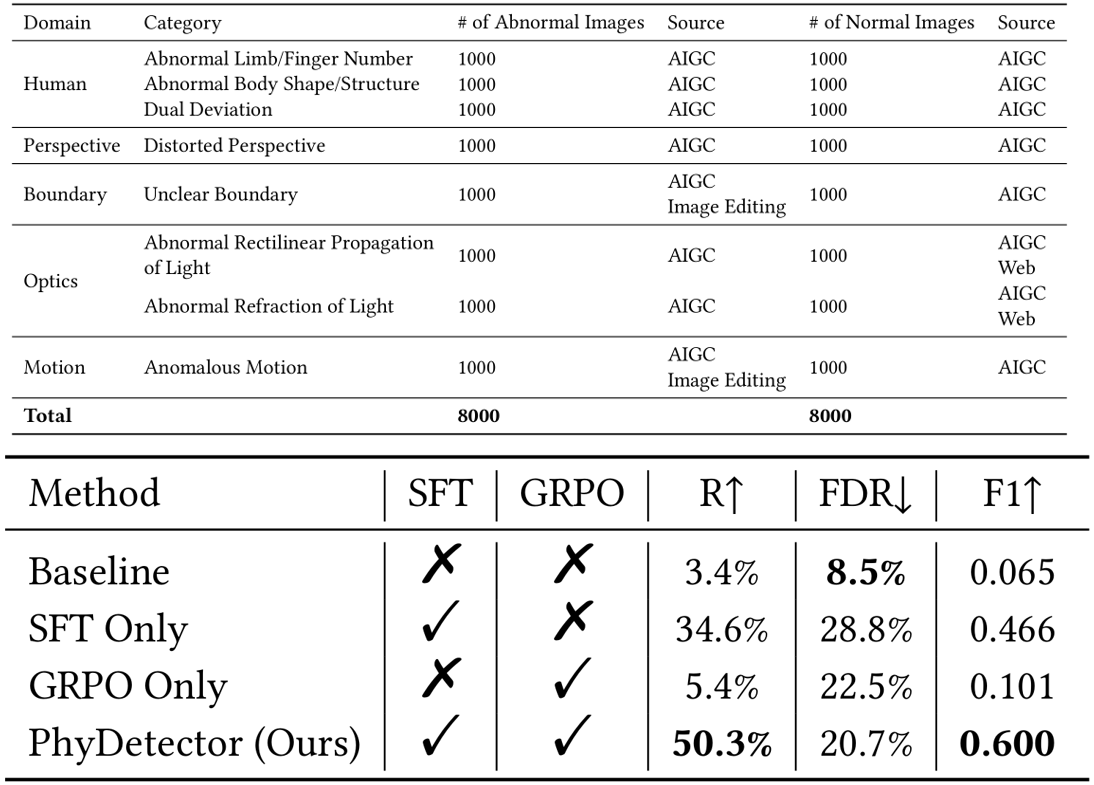
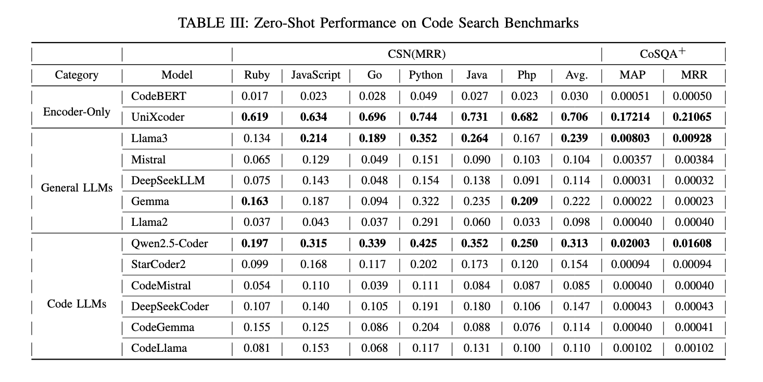
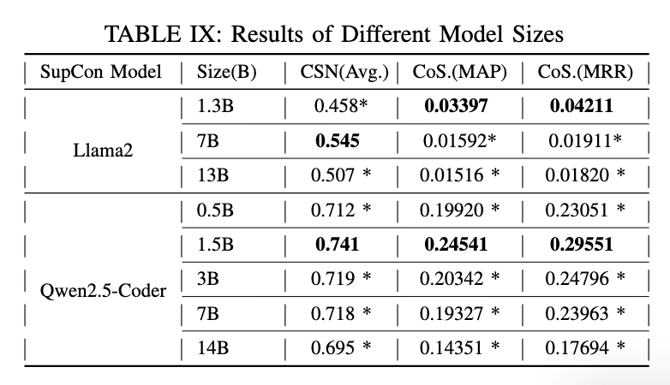
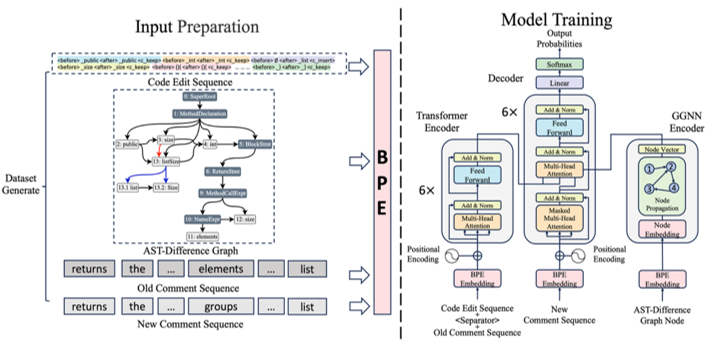
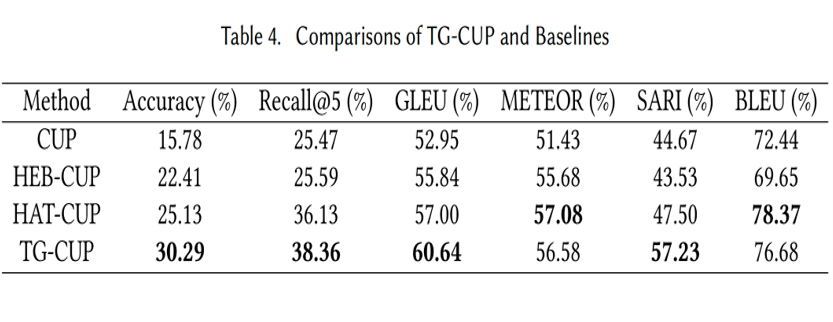
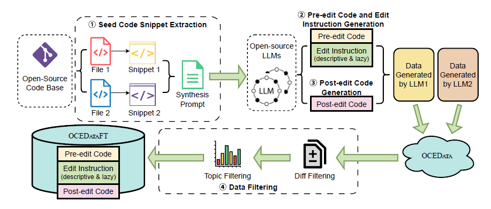
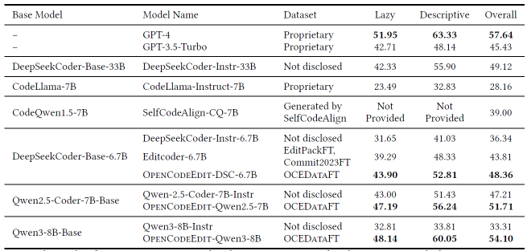
仓库级代码翻译
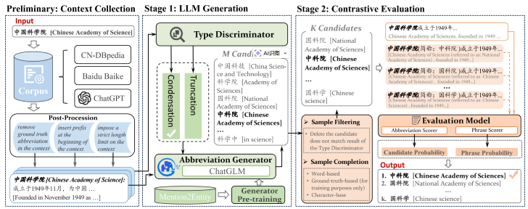
研究问题:研究工业级代码翻译,基于Knowledge-driven 实现仓库级代码翻译智能体
背景痛点
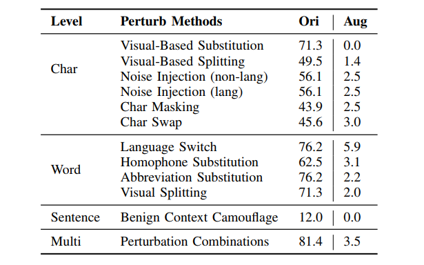
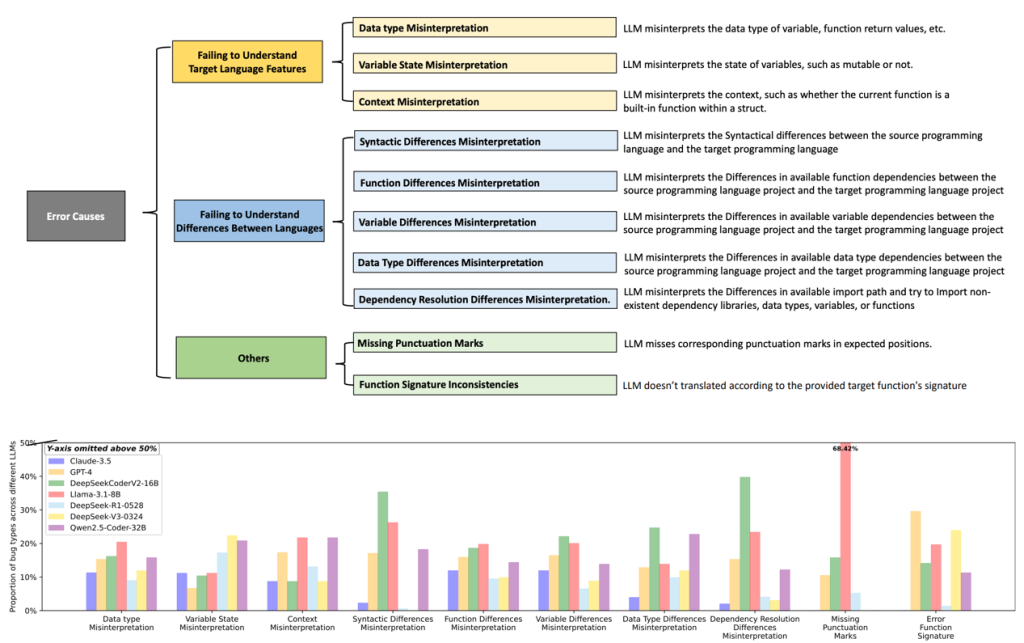
- 翻译场景中仓库级别上下文带来的挑战仍是未知
- 如何有效解决仓库级别上下文带来的问题与挑战仍是未知
解决方案
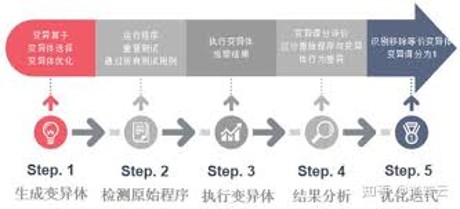
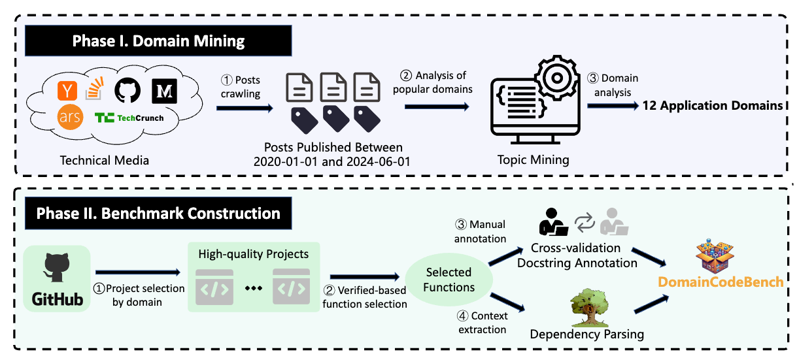
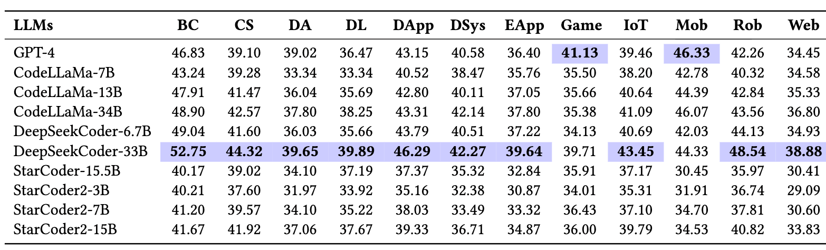
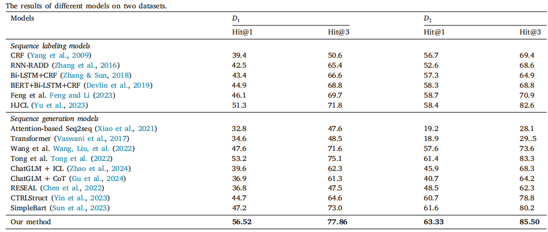
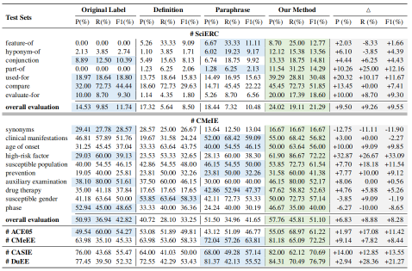
构建全面且细粒度的评估框架和准则
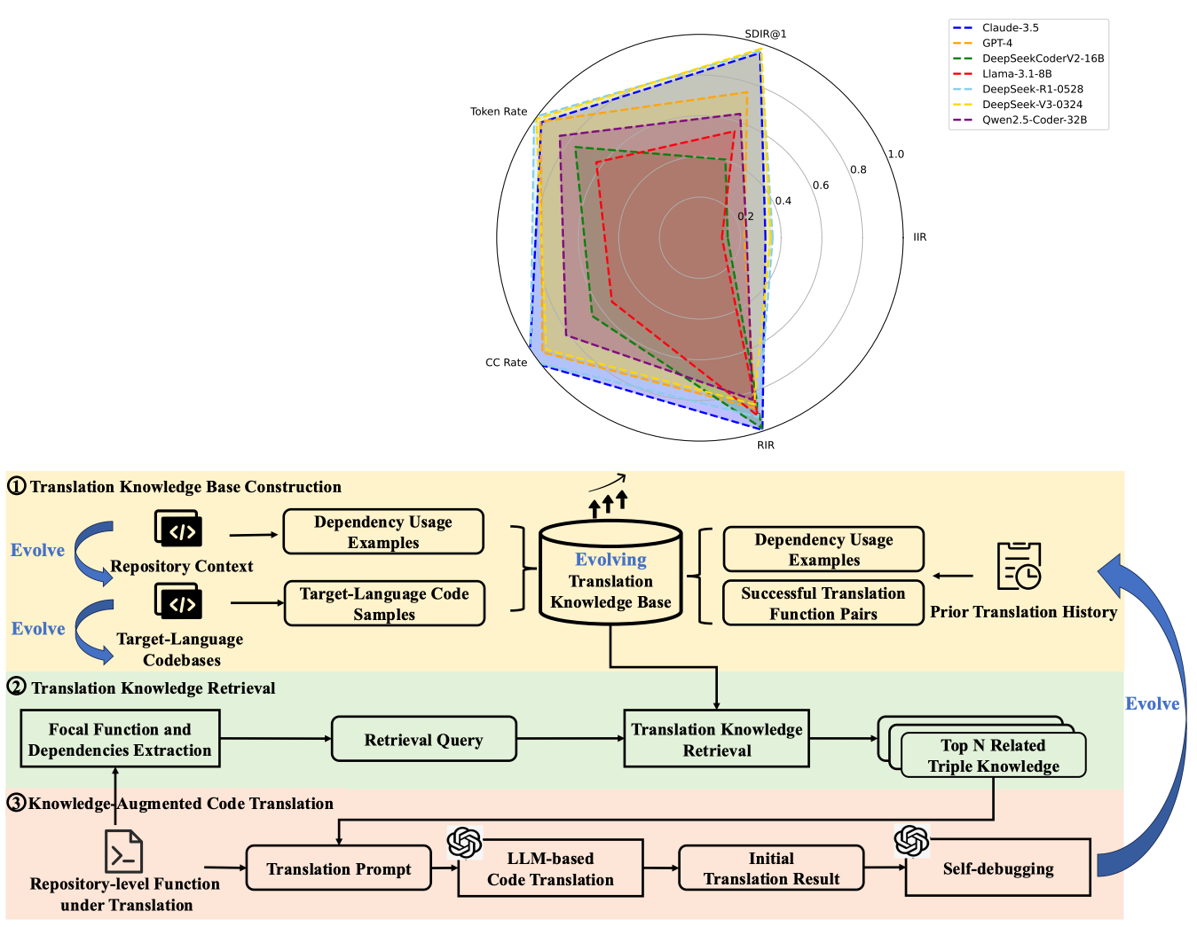
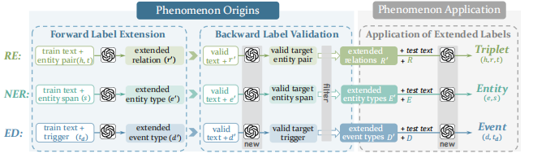
构建基于自演化的三重知识驱动的代码翻译智能体
RustRepoTrans: Repository-level Context Code Translation Benchmark Targeting Rust,ASE2025
K3Trans: Evolving Triple Knowledge-Augmented LLMs for Code Translation in Repository Context, Arxiv